|
|
||
|
|
|
|
|
| 1VRG, FEE, Czech Technical University in Prague |
|
| *Equal contribution | |
|
|
|
|
|
|
|
|
||
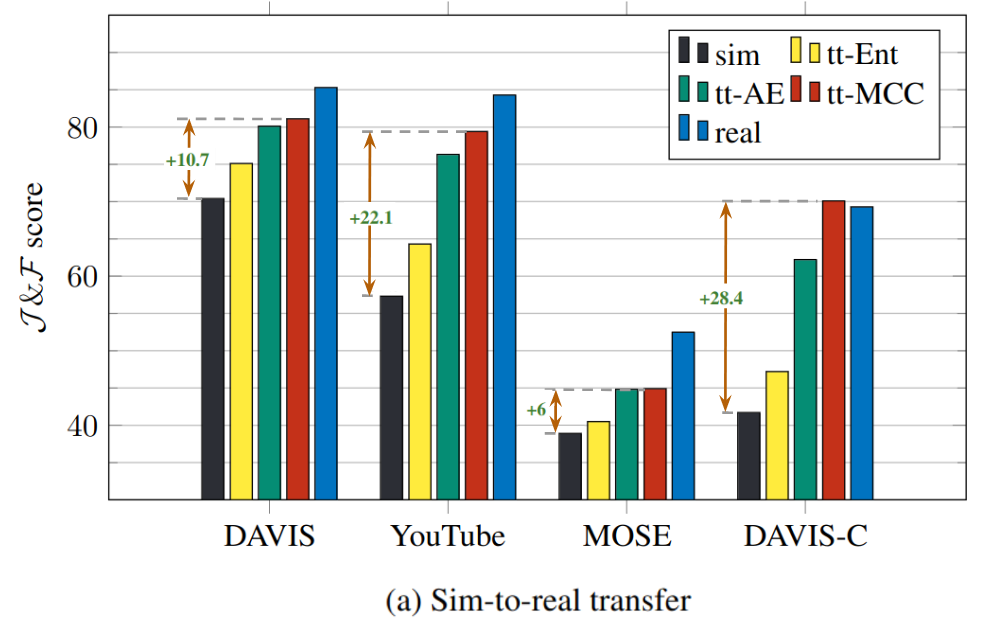
| The video object segmentation (VOS) task involves the segmentation of an object over time based on a single initial mask. Current state-of-the-art approaches use a memory of previously processed frames and rely on matching to estimate segmentation masks of subsequent frames. Lacking any adaptation mechanism, such methods are prone to test-time distribution shifts. This work focuses on matching-based VOS under distribution shifts such as video corruptions, stylization, and sim-to-real transfer. We explore test-time training strategies that are agnostic to the specific task as well as strategies that are designed specifically for VOS. This includes a variant based on MCC tailored to matching-based VOS methods. The experimental results on common benchmarks demonstrate that the proposed test-time training yields significant improvements in performance. In particular for the sim-to-real scenario and despite using only a single test video, our approach manages to recover a substantial portion of the performance gain achieved through training on real videos. Additionally, we introduce DAVIS-C, an augmented version of the popular DAVIS test set, featuring extreme distribution shifts like image-video-level corruptions and stylizations. Our results illustrate that test-time training enhances performance even in these challenging cases. |
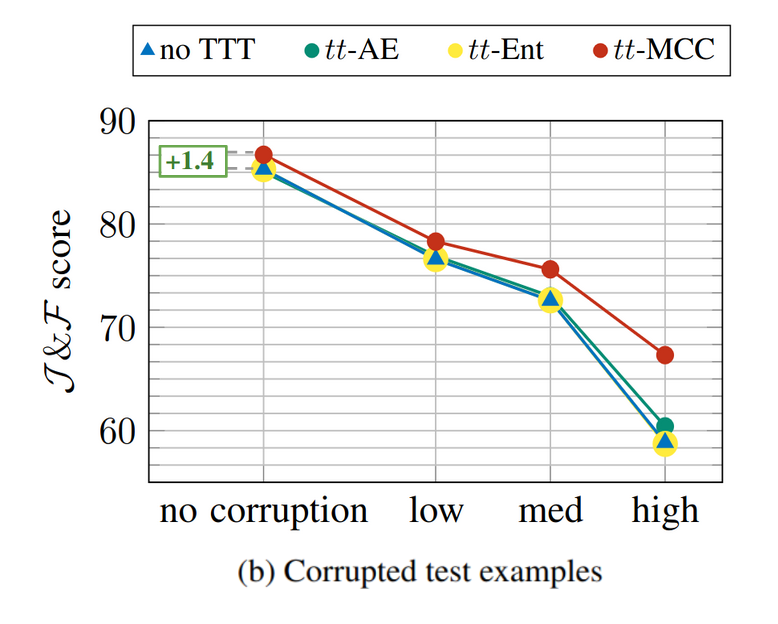
| To model distribution shifts during the testing, we process the set of test videos of the original DAVIS dataset to create the DAVIS-C dataset. This newly created test set offers a test bed for measuring robustness to corrupted input and generalization to previously unseen appearance. It is the outcome of processing the original videos to introduce image-level and video-level corruption and image-level appearance modification. We perform 14 different transformations to each video, each one applied at three different strengths, namely low, medium, and high strength, making it a total of 42 different variants of DAVIS. |

|
|
|
|
|
|

|

|

|
|
|
|
|
|

|

|

|
| More qualitative examples comparing the proposed method (ttMCC) on top of STCN can be found here. |
 |
J. Bertrand, G. Kordopatis Zilos, Y. Kalantidis, G. Tolias. Test-Time Training for Matching-Based Video Object Segmentation. (hosted on Openreview) |
Acknowledgements |